Lecture Note 10. Multi-Way Join Algorithms
Binary join’s performance decreases as the join’s output is larger than its inputs. Worst-case optimal joins (WCOJ) perform join by examining an attribute at a time instead of a relation at a time. The worst-case runtime of the algorithm meets a known lower bound for the worst-case runtime of any join algorithm.
WCOJ has the best runtime of all join algorithm when the query and data represent the worst possible scenario. These joins will be more common because the SQL 2023 standard includes property graph query extensions (see Peter Eisentraut’s overview). For example, finding a path in a graph involves a huge number of self joins.
Adopting Worst-Case Optimal Joins in Relational Database Systems (M. Freitag, et al., VLDB 2020) summarizes WCOJ algorithms and provides its optimized implementation. No TL;DR here.
Lecture Note 09. Hash Join Algorithms
Hash join is the most or one of the most important operator(s) in OLAP DBMS, although not the dominant cost. This lecture focus almost on hash join (partitioned vs non-partitioned), since (1) nested-loop join is always the worst for OLAP and (2) sort-merge join is slower the most of time.
The design goals of hash join on modern hardware are (1) minimize synchronization between threads or cores and (2) minimize memory access cost, especially for remote NUMA access.
Hash Join Phase #1: Partition (optional)
Approach #1: Non-Blocking Partitioning
- Shared Partitions
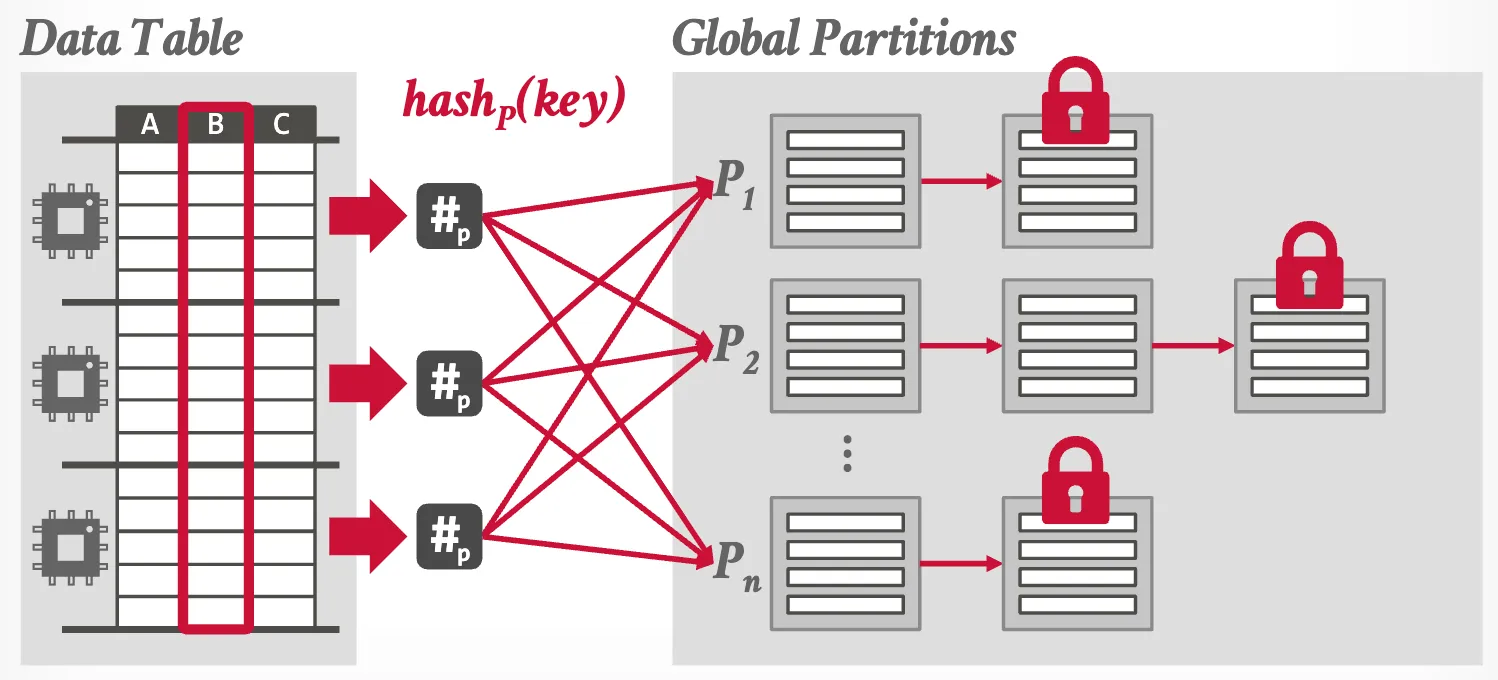
- Private Partitions
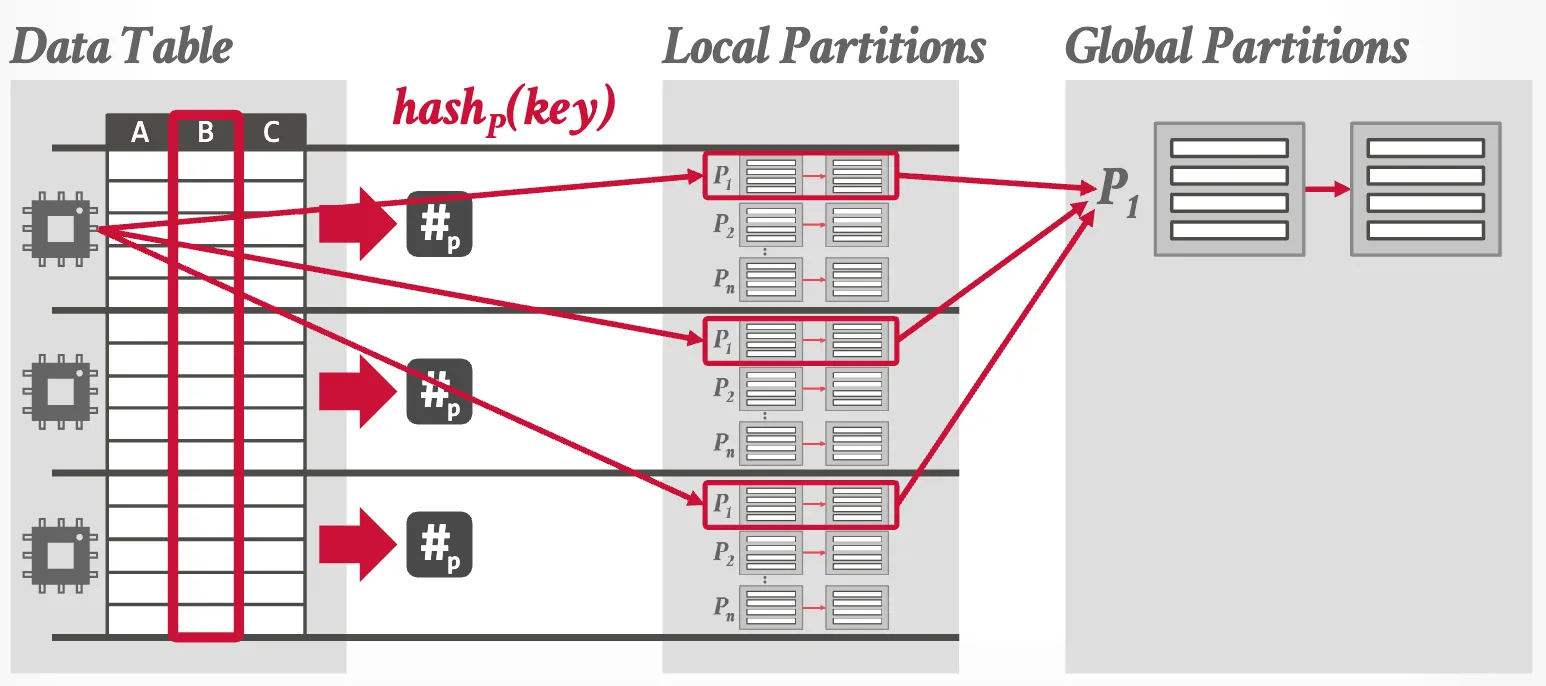
Approach #2: Blocking Partitioning (Radix Hash Join)
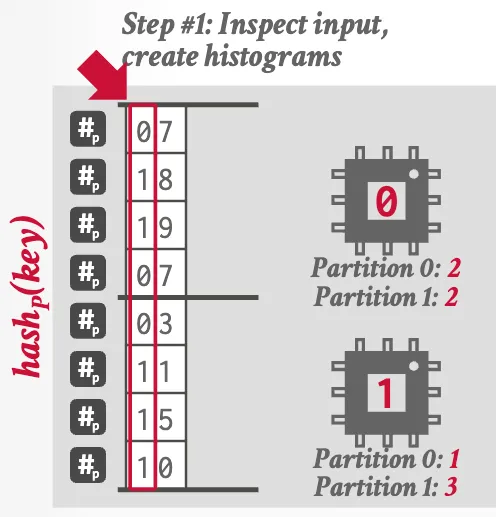
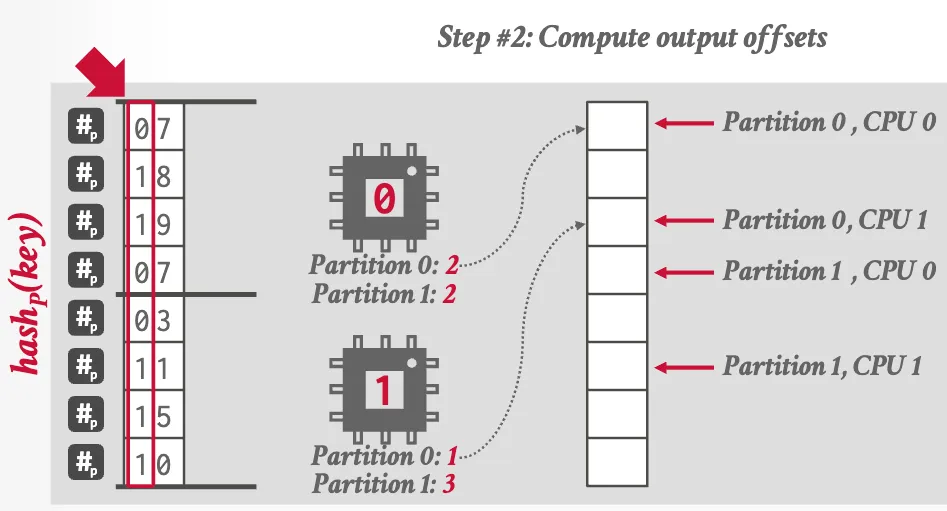
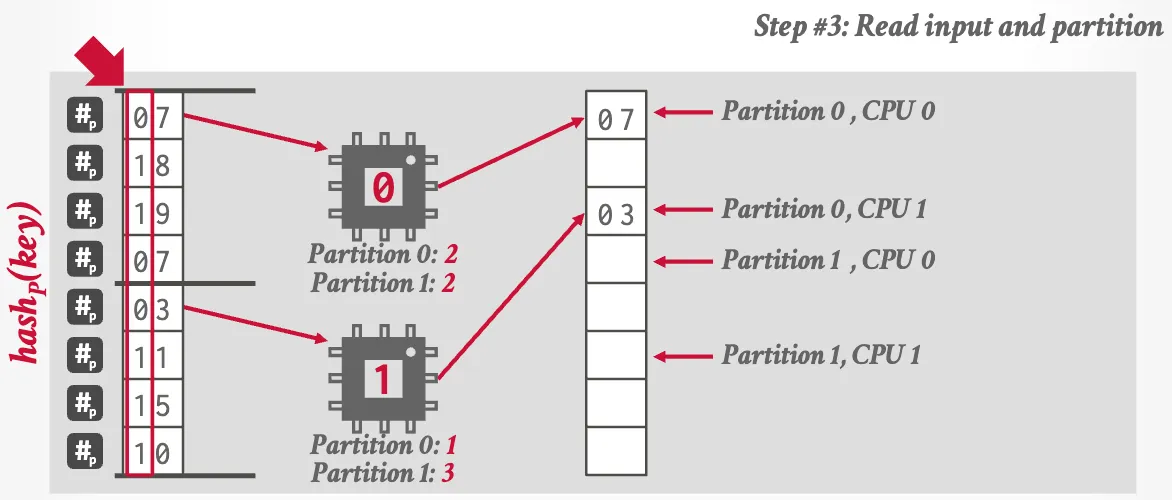
Optimizations:
- Software Write Combine Buffers
- Non-temporal Streaming Writes
Hash Join Phase #2: Build
Hash tables design decisions:
- Hash Function: CRC32, CRC64, xxHash, …
- Hashing Scheme: Chained / Linear / Robin Hood Hashing / Hopscotch Hashing / Cuckoo Hashing
Hash table content trade-offs:
- Tuple Data vs. Pointers/Offsets to Data
- Join Keys-only vs. Join Keys + Hashes
Hash Join Phase #3: Probe
Use bloom filter (as we did everywhere).
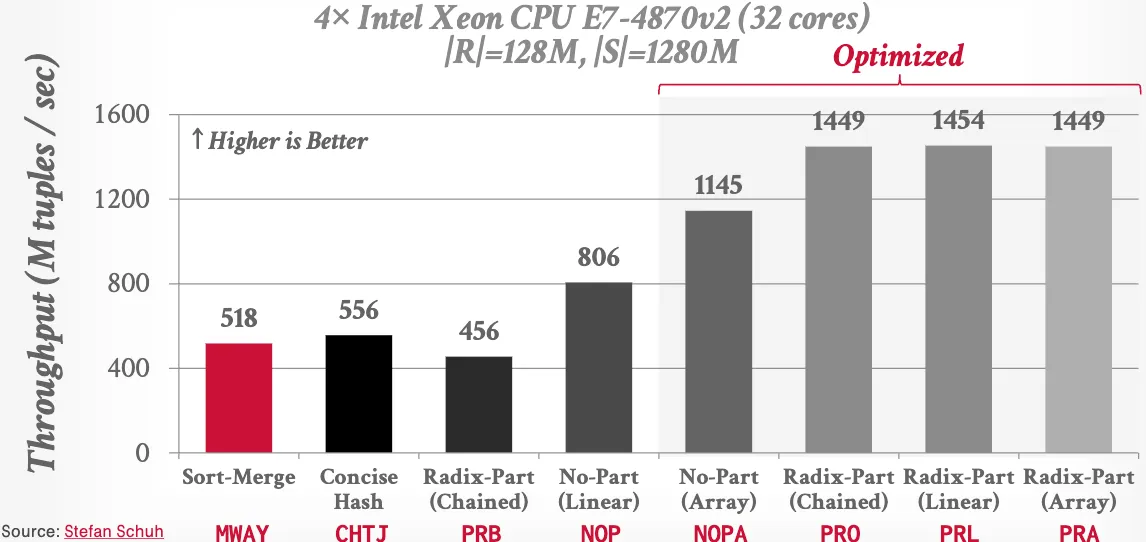
Benchmarks
- Non-partition + linear is generally good.
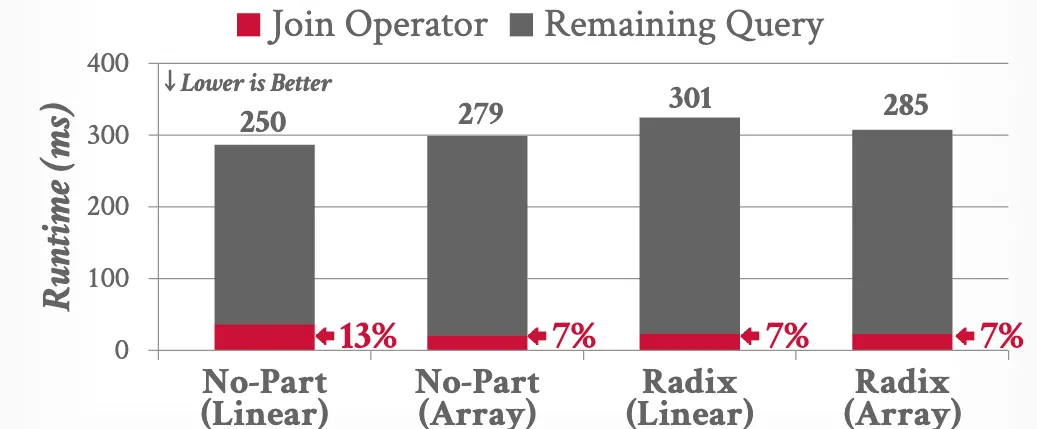
- Join operator is not the dominant cost.
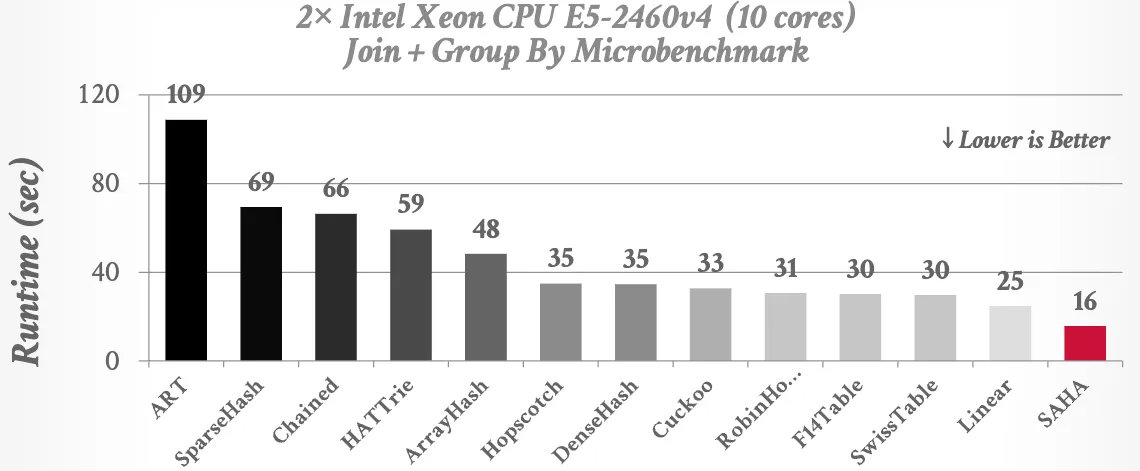
- Linear probe is good, at least for string hash tables.
Lecture Note 07.Code Generation & Compilation
Code Specialization
Generate task-specific code for CPU-intensive task that has a similar execution pattern on different inputs, including:
- Access Methods
- Stored Procedures
- Query Operator Execution
- Predicate Evaluation (most common)
- Logging Operations
Approach #1: Transpilation
Debugging is relatively easy but it takes a relatively long time to compile.
Approach #2: JIT Compilation
HyPer does aggressive operator fusion within pipelines, and compile queries in-memory into native code using the LLVM toolkit.
Reading Review Don’t Hold My Data Hostage: A Case for Client Protocol Redesign (M. Raasveldt, et al., VLDB 2017)
-
Overview of the main idea presented in the paper (3 sentences).
The dominant cost of query that transfers a large amount of data is the cost of result set (de)serialization and network, compared to that of connecting and executing.
While previous works focus on avoiding data exporting, this paper researches on improving result set serialization (RSS).
The authors benchmark the RSS methods of major DBMSs in different network environments, discuss the design choices in RSS method, and purpose a new protocol.
-
Key findings/takeaways from the paper (2-3 sentences).
Both the latency and the throughput of network have the impact on overall performance.
The RSS protocol design space is generally a trade-off between computation and transfer cost.
-
Brief description of the system evaluated in the paper and how it was modified / extended (1 sentence).
The custom protocol serializes the result to column-major chunks and uses a heuristic for determining the compression method.
-
Workloads / benchmarks used in the paper’s evaluation (1 sentence).
TPC-H/American Community Survey (ACS)/Airline On-Time Statistics, each of which has different typical data types and distribution.
Reading Review Efficiently Compiling Efficient Query Plans for Modern Hardware (T. Neumann, VLDB 2011)
-
Overview of the main idea presented in the paper (3 sentences).
As CPU cost became the bottleneck of DBMSs, iterator style query processing shows poor performance due to its lack of locality and frequent instruction mispredictions.
This paper purposes a data centric style processing which try to keep data in CPU registers as long as possible and thus achieve better locality.
The presented framework does aggressive operator fusion within pipelines, and compiled them into native machine code using LLVM IR.
-
Key findings/takeaways from the paper (2-3 sentences).
Pipeline breaker cannot continue processing with CPU registers only, because it either has out-of-the-register input tuple or must materializes all tuples.
The generated code is significantly faster especially for simple query, because of better code quality.
-
Brief description of the system evaluated in the paper and how it was modified / extended (1 sentence).
The presented system employs data centric processing, push based data flow, and code generation using LLVM.
-
Workloads / benchmarks used in the paper’s evaluation (1 sentence).
TPC-CH workload for comparing overall system performance and valgrind emulation for profiling code quality.
Lecture Note 06. Vectorized Query Execution
Implementation Approaches
- Automatic Vectorization
- Compiler Hints (e.g.
restrictin C/C++) - Explicit Vectorization (use CPU intrinsics directly or libraries)
Implementing an algorithm using SIMD is still mostly a manual process.
Vectorization Fundamentals
- Masking
- Permute
- Selective Load/Store
- Compress/Expand
- Selective Gather/Scatter
Vectorized DBMS Algorithms
- Selection Scans
- Vector Refill
- Buffered
- Partial
- Hash Tables
- Partitioning / Histograms
Takeaway: AVX-512 is not always faster than AVX2 due to clock speed downgrade.
Reading Review Make the Most out of Your SIMD Investments: Counter Control Flow Divergence in Compiled Query Pipelines (H. Lang, et al., VLDB Journal 2020)
-
Overview of the main idea presented in the paper (3 sentences).
SIMD instructions are widely intergrated with database systems today, but the underutilization due to control flow divergence causes the performance degradation in compiling database systems. This paper presents an algorithm using AVX-512 instructions to refill the inactive SIMD lanes and also purposes two strategies to integrate this algorithm into the query compilation process. The evaluation shows the considerable performance improvement and suggests a hybrid approach to be optimal for different workloads.
-
Key findings/takeaways from the paper (2-3 sentences).
The partial consume strategy works for relatively simple workloads but may cause performance degradation for complex workloads, because of the underutilization caused by protected lanes and a potential suboptimal memory access pattern on refill.
Refill algorithms and strategies are generally applicable to any data processing system that uses AVX-512 SIMD instructions, e.g. Apache Arrow.
-
Brief description of the system evaluated in the paper and how it was modified / extended (1 sentence).
The modified system buffers or remains the active SIMD lanes in the SIMD register and refill the inactive lanes with the values from memory or other SIMD registers.
-
Workloads / benchmarks used in the paper’s evaluation (1 sentence).
(1) A table scan query based on TPC-H Query 1, (2) a hashjoin query, and (3) an approximate geospatial join query.
Lecture Note 05. Query Execution & Processing II
This lecture is a quick overview of more design considerations when building an execution engine.
Parallel Execution
-
Inter-Query Parallelism allows multiple queries to execute simultaneously
-
Intra-Query Parallelism executes the operators of a single query in parallel
-
Intra-Operator (Horizontal)
Coalesce results from children operators by an exchange operator, types of which can be gather, distribute or repartition.
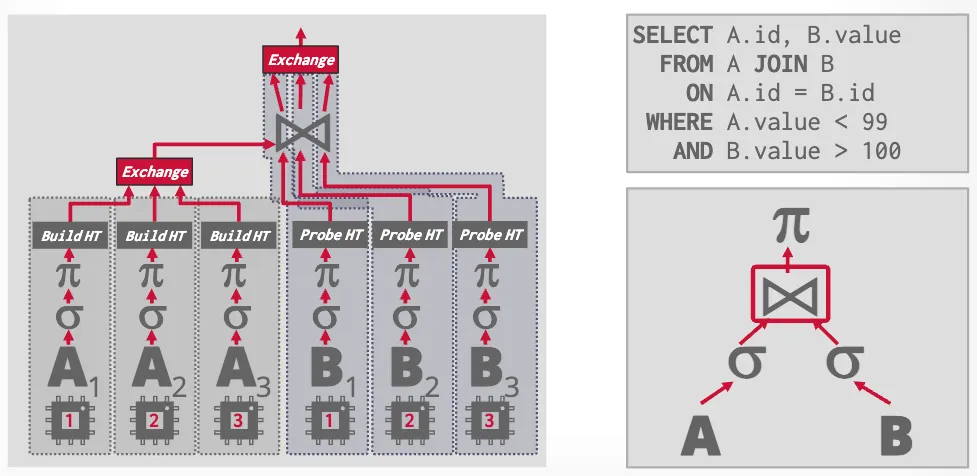
-
Inter-Operator (Vertical) or Pipeline Parallelism
-
Operator Output
-
Early Materialization

-
Late Materialization
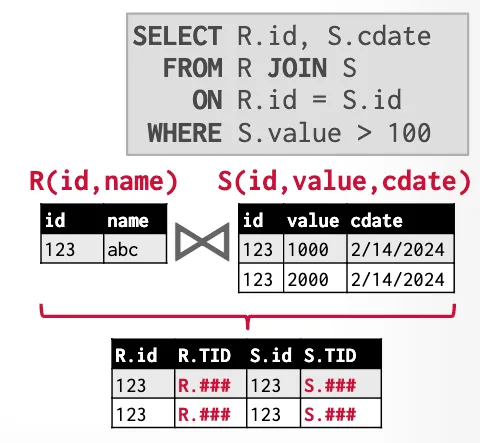
Internal Representation
The DBMS cannot use the on-disk file format (Parquet or ORC) for execution directly. Instead, it converts the data into an in-memory internal representation and then propagates the data through the query plan.
Apache Arrow is the best choice for internal data representation (Andy’s opinion). It’s a self-describing, language-agnostic in-memory columnar data format, which is optimized for cache-efficient and vectorized execution engines.
Expression Evaluation
Instead of traversing the expression tree for each tuple, Velox uses JIT compilation to evaluate the expression directly.
Adaptive Execution
Adaptive Execution is a technique that allows to modify a query’s plan and expression tree on execution based on the information gathered during the execution.
Tricks used in Velox:
- Predicate Reordering decides the ordering of predicates based on their selectivity and computational cost
- Column Prefetching
- Not Null Fast Paths skips null checking if input vector has no null values (known from the filter vector)
- Elide ASCII Encoding Checks
Reading Review Velox: Meta’s Unified Execution Engine (P. Pedreira, et al., VLDB 2022)
-
Overview of the main idea presented in the paper (3 sentences).
Computation engines targeted to specific data workloads (e.g. analytical processing, realtime stream processing, AI/ML systems) share little with each other, causing inconsistent user interfaces and engineering waste.
This paper proposes an reusable and extensible query execution library, and presents its usage in different systems of Meta.
Thanks to the modular-style design and implementation, its components can be used independently or extended by plugins, based on the functionality required.
-
Brief description of the system evaluated in the paper and how it was modified / extended (1 sentence).
The Velox provides high-level components (type, vector, expression eval, functions, operators, etc.), each of which provides extensibility APIs to add plugins.
-
Workloads / benchmarks used in the paper’s evaluation (1 sentence).
Comparing the new C++ Velox-based execution engine with the current Presto Java implementation using CPU-bound queries and shuffle/IO heavy queries on the TPC-H dataset.
I request for my privilege to miss the reading review for MonetDB/X100 paper, since Andy said most OLAP DBs today followed the guidelines in that paper (no suprise, this paper is as old as me).
Lecture Note 04. Query Execution & Processing I
DBMS engineering is an orchestration of a bunch of optimizations and not a single one is more important than the others.
Overview optimization goals:
- Reduce Instruction Count. Compiler optimizations, better coding.
- Reduce Cycles per Instruction. Branchless, SIMD, dependent-free.
- Parallelize Execution.
MonetDB/X100 Analysis
Modern CPUs organize instructions into pipeline stages and support multiple pipelines. The problems in DBMS are (1)dependencies in instruction and (2)branch misprediction.
Example solutions:
-
Branchless selection scans.

-
Excessive instructions. No big switch table.
Processing Models
Processing model = control flow + data flow.
-
Iterator Model (Volcano / Pipeline Model)
op.next()returns one tuples at a time. -
Materialization Model
op.output()returns the whole result set. -
Vectorized / Batch Model
op.next()returns a batch of tuples. Ideal for OLAP queries.
Plan Processing Direction
-
Top-to-Bottom (Pull)
-
Bottom-to-Top (Push)
More in HyPer system next week.
Filter Representation
-
Selection Vectors
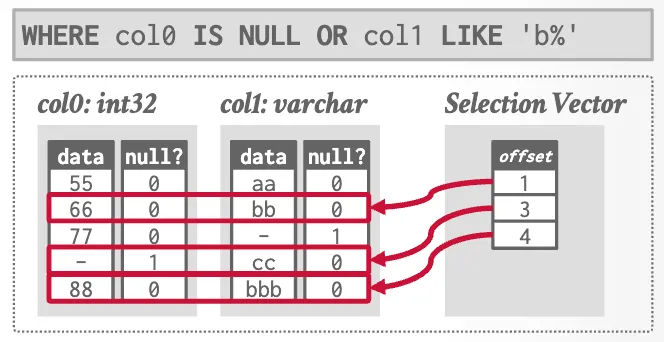
-
Bitmaps
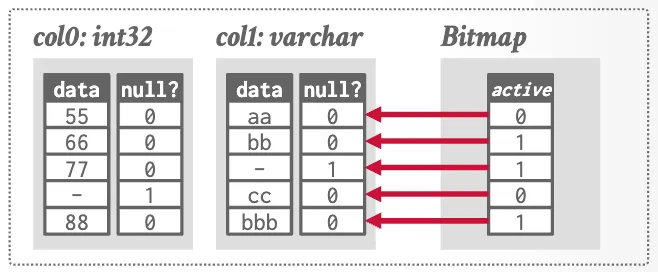
Vectorized / bottom-up execution almost always will be the better way to execute OLAP queries.
Lecture Note 03. Data Formats & Encoding II
I try to read the papers before class, but it’s hard to understand (FastLane in particular). I decide to watch the video first but just to find this lecture is mainly about that 3 papers…😅 Thus this note will just simply cover the main idea.
Nested Data Representation (from last class)
- Shredding
- Length + Presence
Critiques of Existing Formats
- Variable-sizes runs is not SIMD friendly.
- No random access if using block compression.
- Dependencies between adjacent values.
- Not designed for SIMD of all ISAs.
The Ideas from Papers
The ideas from the 3 papers to solve these challenges:
-
BtrBlocks
To select a better encoding scheme, sample values from column, try out all viable encoding schemes, and repeat three times.
Among the encoding schemes:
- FSST Replace frequently occurring substrings with 1-byte codes.
- Roaring Bitmaps Use a hierarchical bitmap (like page table in kernel). Bitmap for dense chunks; array for sparse chunks.
-
FastLanes
Reordering data layout to achieve parallelism.
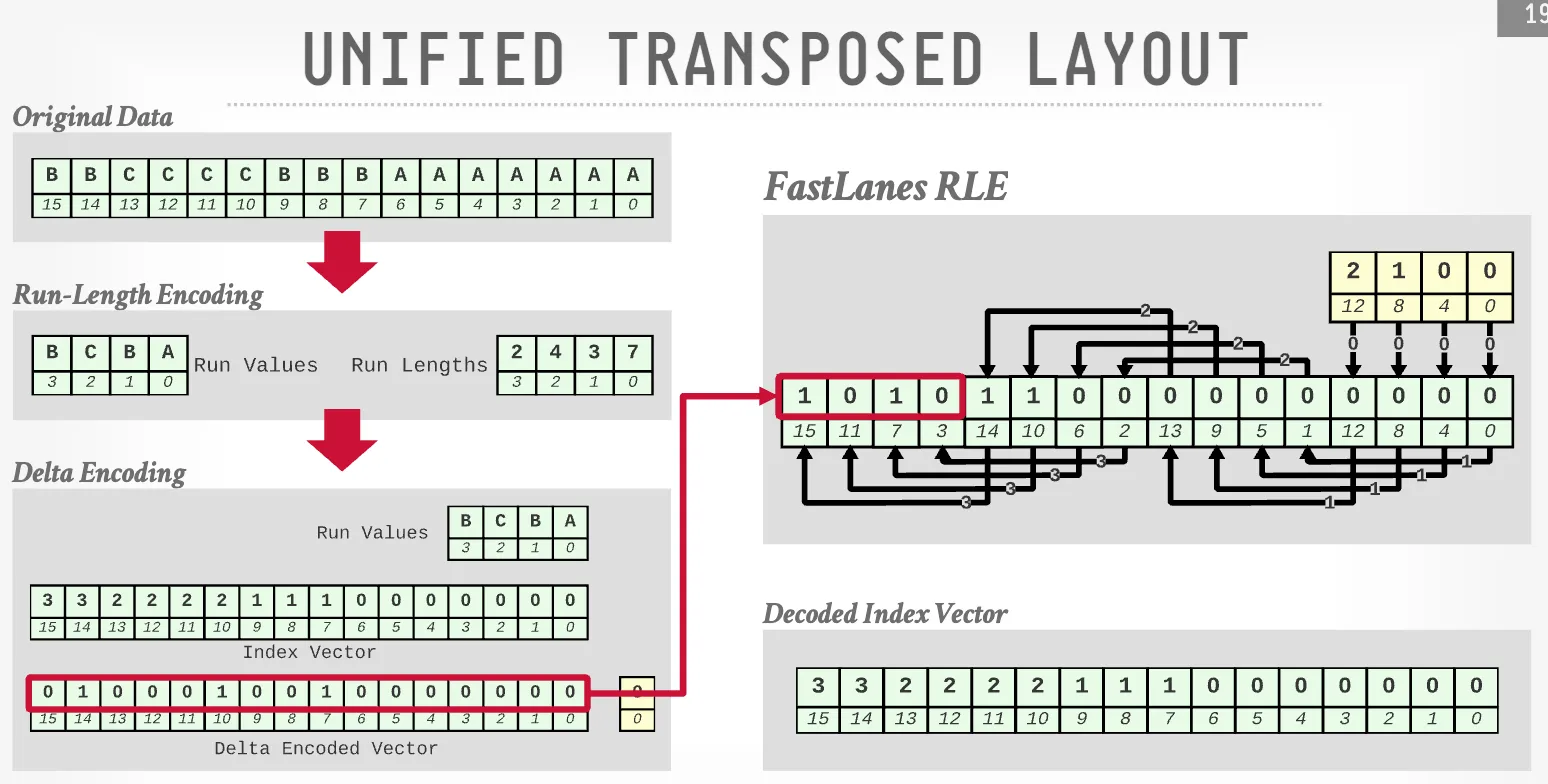
-
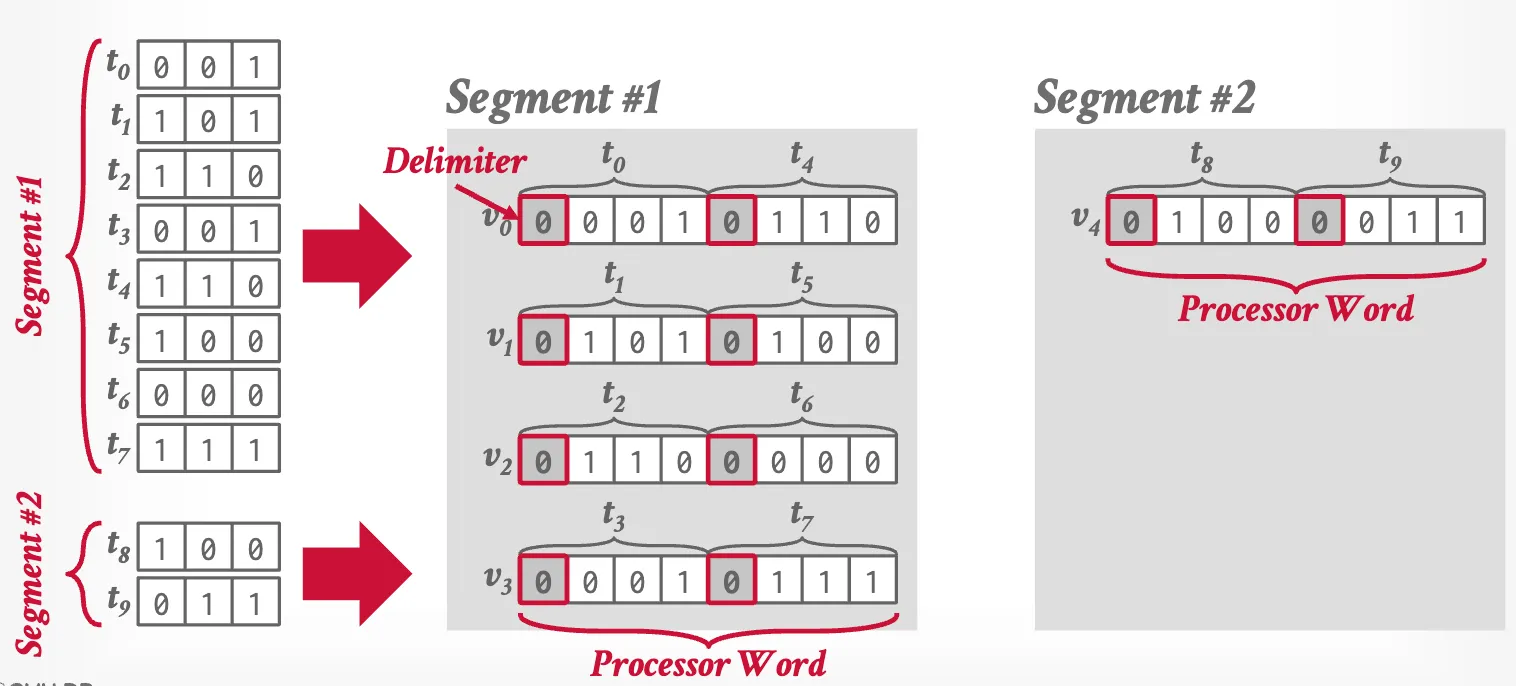
BitWeaving
Implement “short-circuit” comparisons in integer type using CPU instructions (capable of extendind to SIMD).
The integer stores in bit-sliced encoding, where a logical integer column is stored as multiple bit columns (physically).
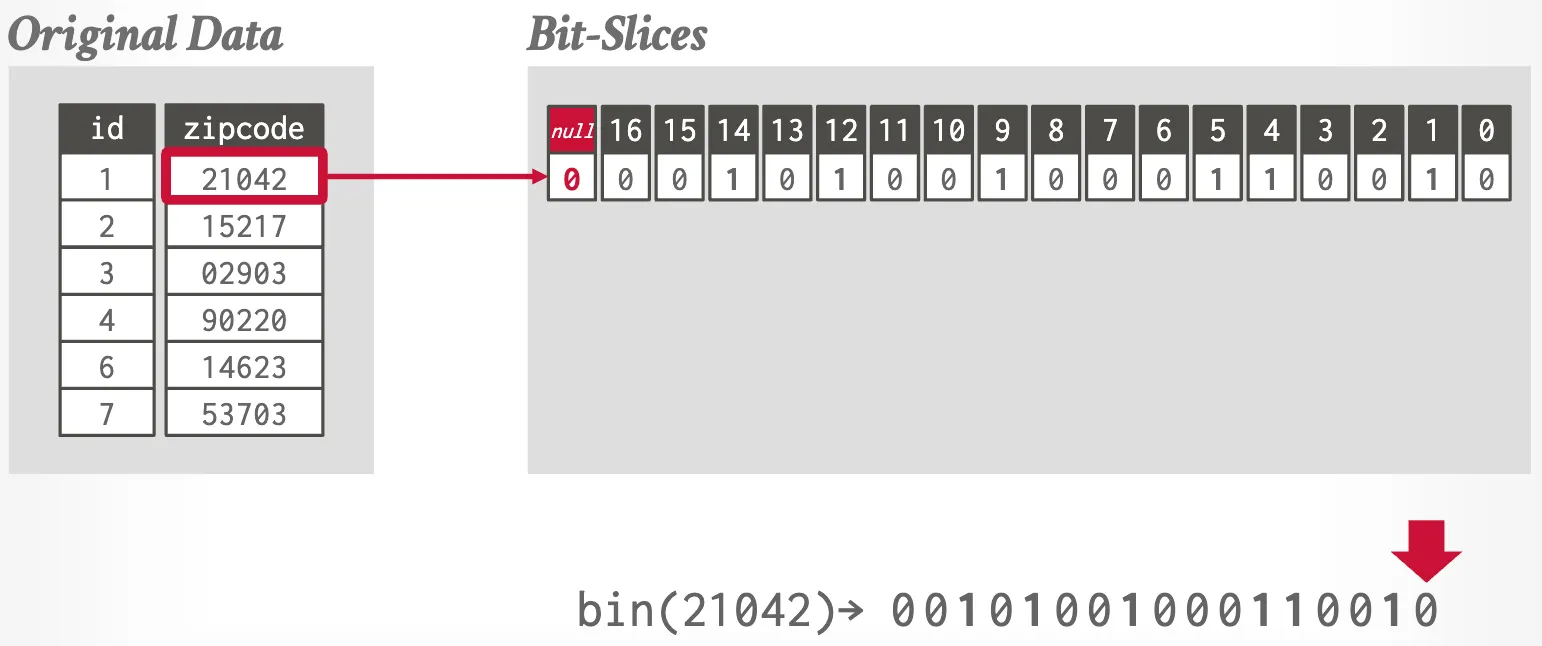
Employ bit hack to perform prediction using SIMD instructions.
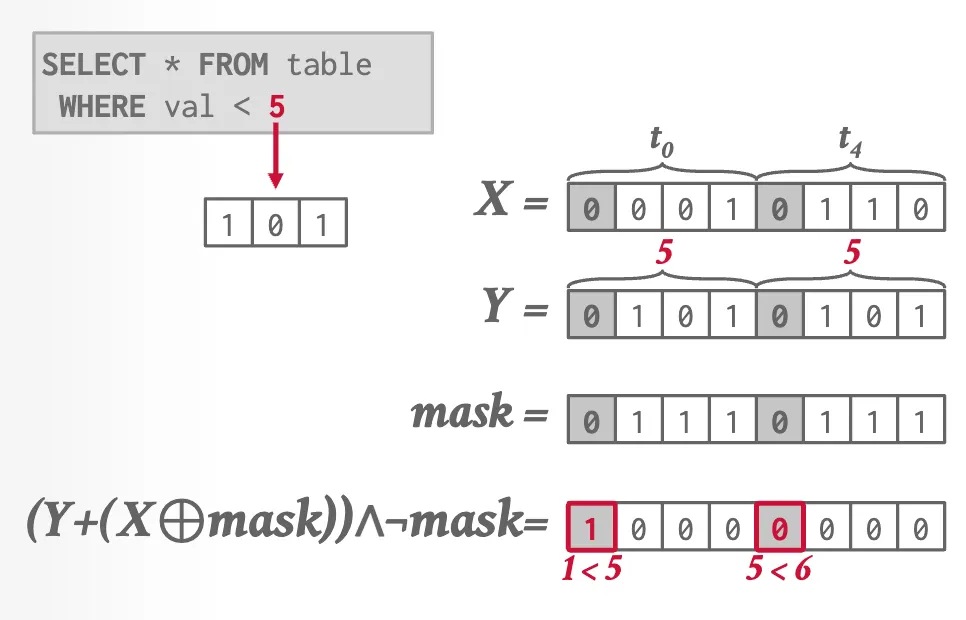
Lesson Learned
Logical-physical data independence allows hacking on physical representation/computation without logical interfaces changed.
Data parallelism via SIMD is an important tool.
Lecture Note 02. Data Formats & Encoding I
OLAP workloads tends to do sequential scans on large segments of read-only data, while OLTP workloads mostly find individual tuples.
Sequential scan optimizations:
- data encoding / compression (this lecture)
- data parallelization / vectorization (next lecture)
- code specialization / compilation (later this semeter)
- prefetching, clustering / sorting, late materialization, materialized views / result caching… (intro class)
Storage Models
- NSM (N-ary Storage Model)
- tuple continuously
- ideal for OLTP workloads (access individual entities / insert-heavy)
- fixed page size
- most OLTP DBMSs (PG, MySQL, Oracle)
- DSM (Decomposition Storage Model)
- attribute continuously
- ideal for OLAP (query a subset of attributes)
- fixed-length offsets over embedded tuple IDs (How to convert variable-length data into fixed-length? Dictionary compression over padding)
- PAX (Partition Attributes Across)
- hybrid, row groups + column chunks
- faster processing + spatial locality
Persistent Data Format
Design decisions from Apache Parquet / Apache ORC:
- Meta-data Self-contained over ‘catalog + data’. Global meta-data included in each group: table schemas, row group offsets / length, tuple counts / zone maps, etc.
- Format layout PAX.
- Type system Physical type vs. logical type (e.g. integer vs. timestamp)
- Encoding scheme Dictionary compression.
- Block compression Computational overhead is over network / disk.
- Filter Zone maps and bloom filters.
- Nested data
Lessons learned:
- Dictionary encoding is effective for all data types.
- Simplistic encoding schemes are better on modern hardwares.
- Avoid general-purpose block compression since network / disk are no longer the bottleneck relative to CPU performance.
Reading Review An Empirical Evaluation of Columnar Storage Formats (X. Zeng, et al., VLDB 2023)
-
Overview of the main idea presented in the paper (3 sentences).
Widely adopted open-source columnar storage formats were developed over 10 years ago, since then both hareware and workload lanscapes have changed. The authors develop a framework to generate workloads, which has a similar value distribution as real-world workloads. Using those workloads as benchmark, this paper compares the performance and space efficiency between Parquet and ORC.
-
Key findings/takeaways from the paper (2-3 sentences).
- Beneficial design decisions: (1)using dictionary encoding, (2)favoring decoding speed over compression ratio for integer encoding algorithms, (3)making block compression optional, and (4)embedding finer-grained auxiliary data structures.
- Most widely adopted formats are not optimized for common ML workloads and GPUs decoding.
-
Brief description of the system evaluated in the paper and how it was modified / extended (1 sentence).
N/A
-
Workloads / benchmarks used in the paper’s evaluation (1 sentence).
In the real-world liked workloads, the benchmark tests the data process performance and the space efficiency of Parquet and ORC format.
Lecture Note 01. Modern Analytical Database Systems
History
-
Data Cube (’90s)
DBMSs maintain pre-computed aggregations to speed up queries.
-
Data Warehouses (’00s)
- Monolithic DBMSs
- Shared-nonthing architectures
- Column-oriented data storage
- ETL data from OLTP databases into OLTP database
-
Shared-Disk Engines (’10s)
- Shared-disk architectures
- Third-party distributed storage instead of custom storage manager
- OLTP databases store data in object store (with catalog manager); OLAP query engine fetches data from that
-
Lakehouse Systems (’20s)
- SQL as well as non-SQL
- decoupling data storage from DBMS
- Unstructured / semi-structured data
Components
- System Catalogs
- Intermediate Representation
- Query Optimizers
- File Format
- Access Libraries
- Execution Engines / Fabrics
(Distributed) Architecture
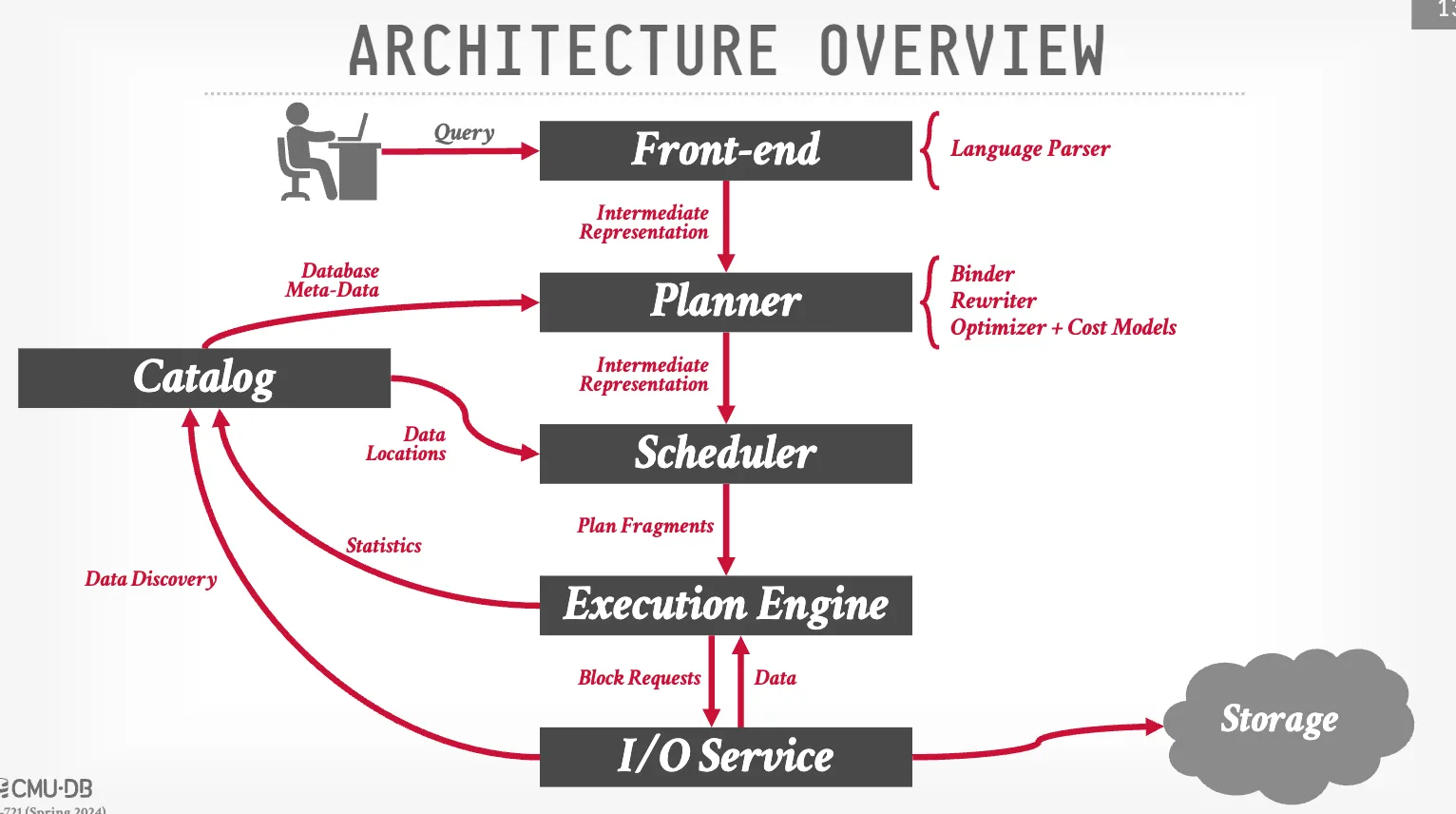
Distributed OLAP query execution is roughly the same as that on single node. For each operator the DBMS considers where to fetch the input and where to send the output.
-
Persistent Data & Intermediate Data
-
Push Query to Data vs. Pull Data to Query
-
Shared-Nothing vs. Shared-Disk
- Shared-Nothing
- Harder to scale capacity
- Better performance & efficiency (potentially)
- Filtering data before transferring
- Shared-Disk
- Scalable compute layer
- Not pay for idle compute nodes
- No filtering before pulling (more and more supports now)
Most OLAP DBMSs today uses the shared-disk architecture because of object stores (cheaper and infinitely scalable). Caching can reduce the performance lost.
- Shared-Nothing
Reading Review The Composable Data Management System Manifesto (P. Pedreira, et al., VLDB 2023)
-
Overview of the main idea presented in the paper (3 sentences).
Specialized data management systems have been rapidly invented and developed for different workloads. The lack of reusing design and components in these systems causes many problems, including incompatible SQL/non-SQL API and inconsistent semantic between different systems. This paper advocates a composable paradigm in data management systems and purposes a modular architecture.
-
Key findings/takeaways from the paper (2-3 sentences).
- A modular data stack consists of a components which are reused in different data management systems.
- A well-defined and system-agnostic intermediate representation (IR) to seperate language and execution.
-
Brief description of the system evaluated in the paper and how it was modified / extended (1 sentence).
Seperate the monolith data systems into a modular data stack consists of a language frontend, an intermediate representation (IR), a query optimizer, an execution engine and an execution runtime.
-
Workloads / benchmarks used in the paper’s evaluation (1 sentence).
N/A
Reading Review Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics (M. Armbrust, et al., CIDR 2021)
-
Overview of the main idea presented in the paper (3 sentences).
The 2-tier data lake + warehouse architecture with complex ETL process suffers from data inconsistence/staleness and other problems. This paper presents an unified data warehouse architecture, which stores data in a low-cost object storage using open direct-access format. Optimizations like caching and indexing on top of a metadata layer allow this system to achieve competitve performance.
-
Key findings/takeaways from the paper (2-3 sentences).
- Standard data format allows different kinds of application to directly access data and thus avoids data staleness.
- Metadata layer provides traditional DBMS data management features (e.g. ACID transactions) and allows performance optimizations.
-
Brief description of the system evaluated in the paper and how it was modified / extended (1 sentence).
Lakehouse stores data in a low-cost object storage (S3 in particular) using a open direct-access data format and builds a transactional metadata layer to implements management features.
-
Workloads / benchmarks used in the paper’s evaluation (1 sentence).
TPC-DS power time and cost among popular cloud data warehouses.